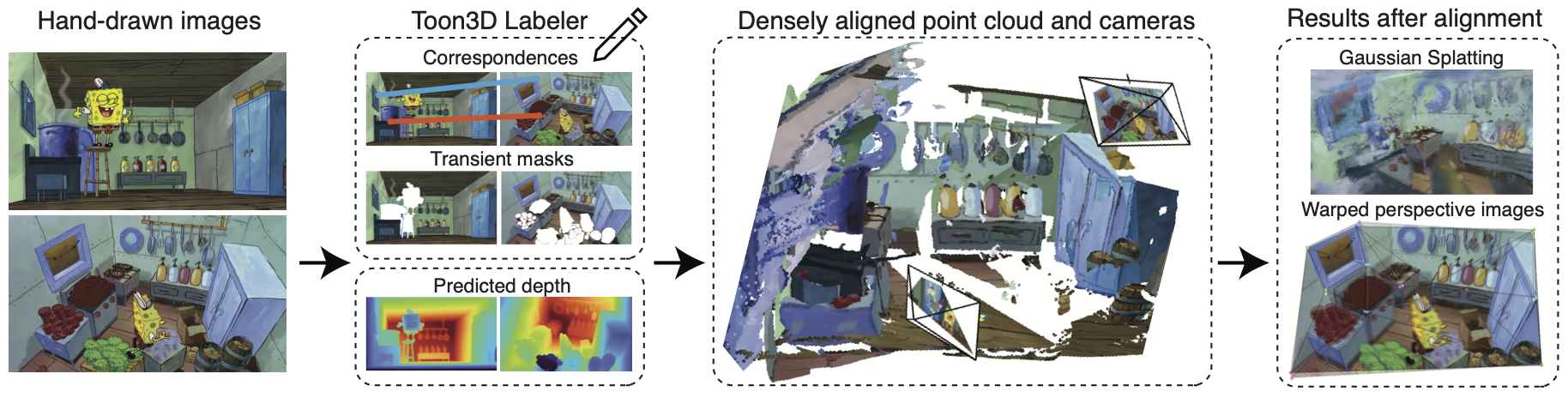
Humans can perceive 3D world from images that aren't 3D consistent, but machines cannot. Let's fix
this!
COLMAP fails to reconstruct non-geometric hand-drawn images, even with perfect
correspondences! Other methods, including Bundle Adjustment and DUSt3R, perform very badly. We compare
with these baselines both qualitatively and quantitatiely, and we find our method to be superior. Please
watch the video to understand our problem setting and read the paper for more details! We also include
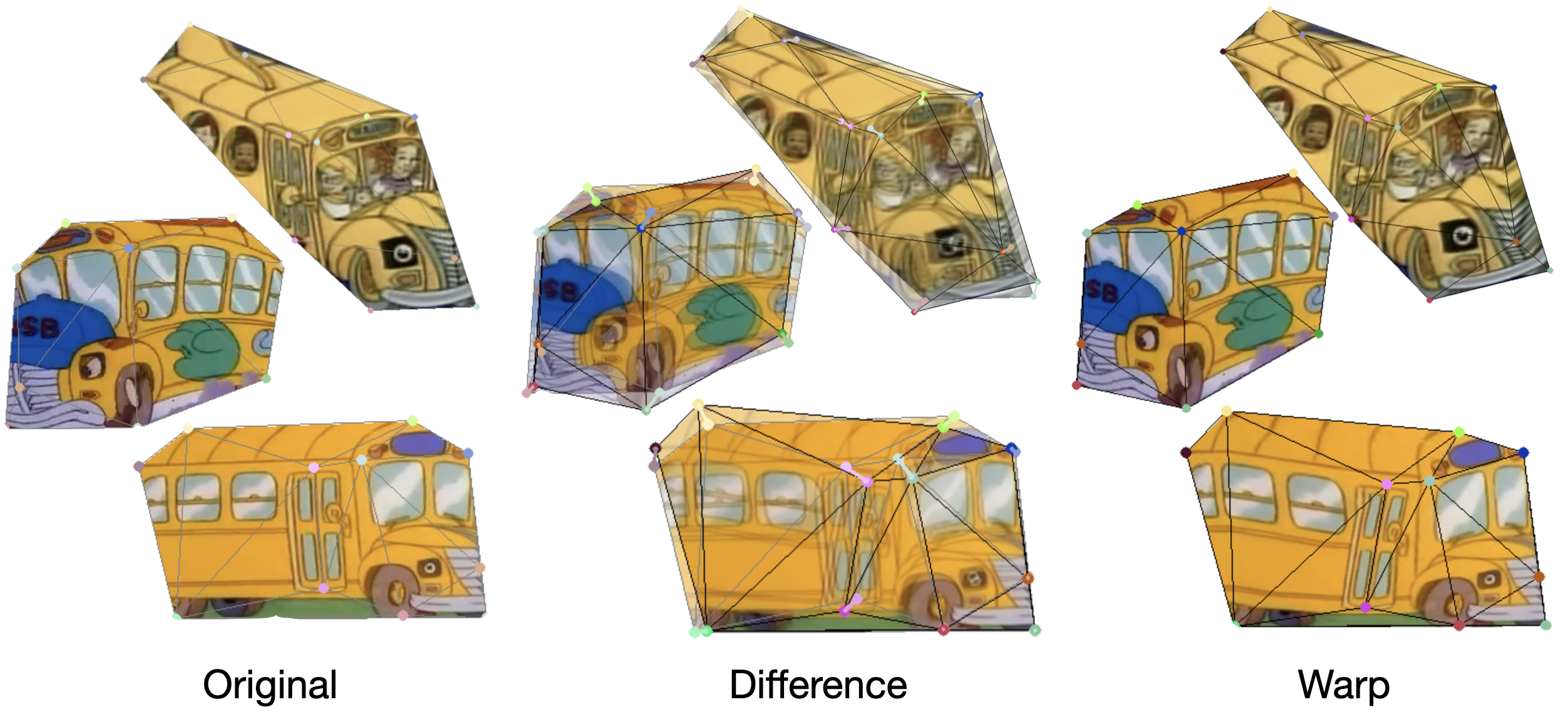
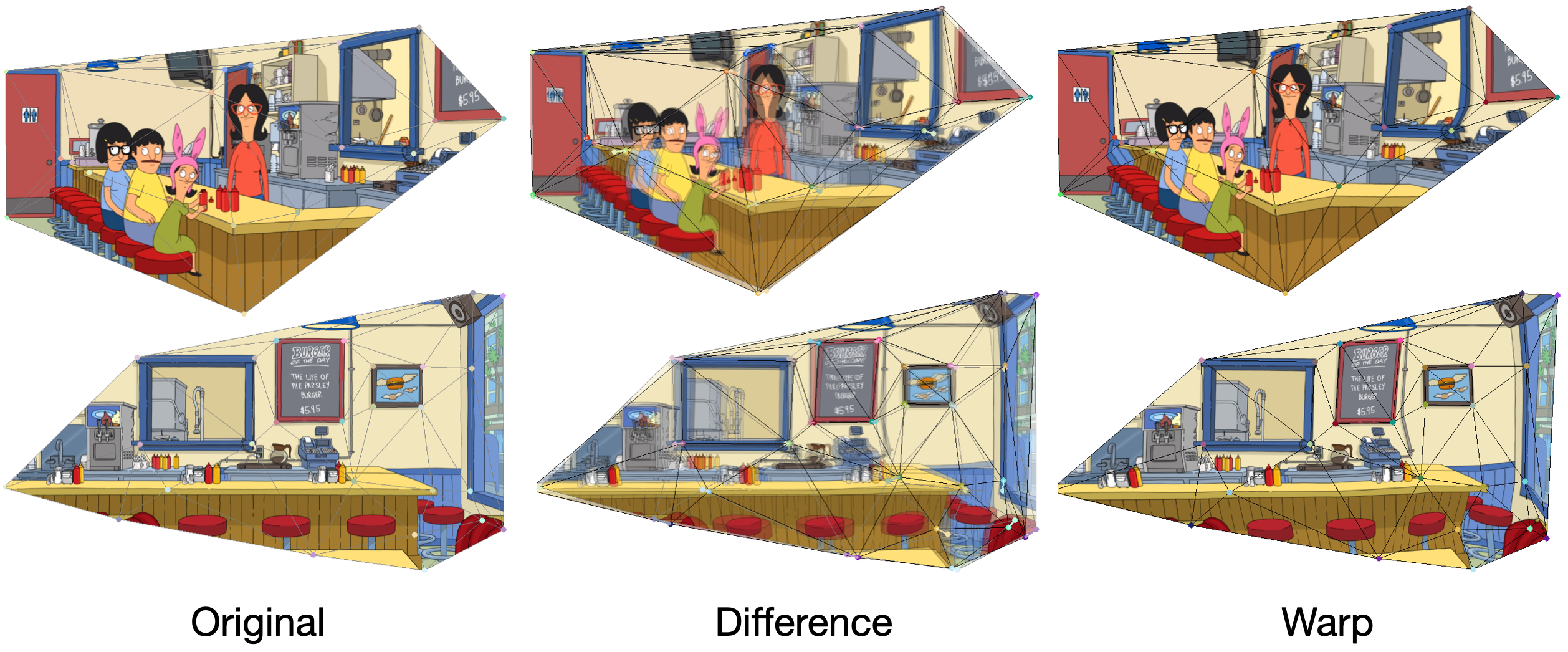
an ablation study in the paper to provide insights about our method.
Overview Video
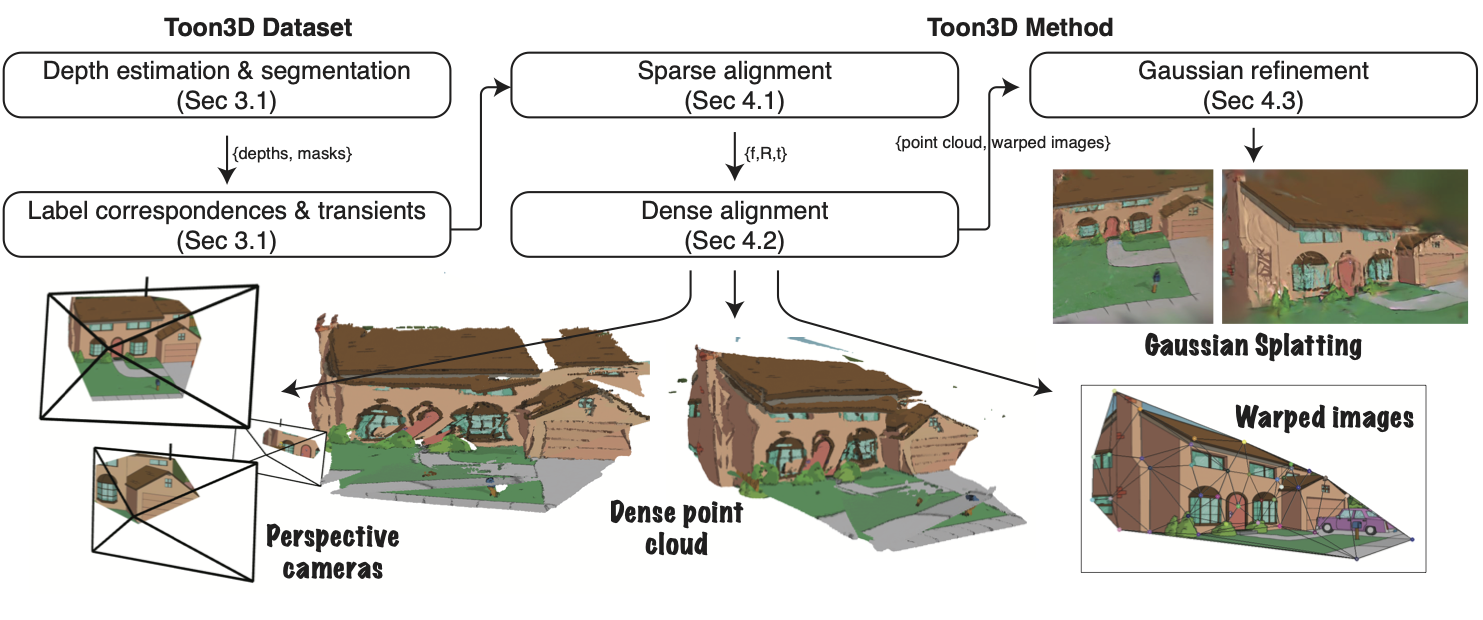
Framework Overview